核心概念
让我们深入 Turbopack 内部了解为什么它如此之快吧。
Turbo 引擎
Turbopack 之所以这么快是因为它建立在一个可复用的 Rust Library 之上,也就是所谓的 Turbo 引擎,使其支持递增式计算。它的运作方式:
函数级缓存
在由 Turbo 驱动的程序里,你可以给特定某些函数打上「记忆」标签。当这些函数被调用时,Turbo 引擎将记住它们调用方式及其返回值。这些状态都将缓存到内存里。
下面是一个工具构建流程经简化的例子

首先,我们对 api.ts 和 sdk.ts 两个文件调用 readFile 函数。对这两个进行 构建 后,再将它们 合并 起来,最后得到了 fullBundle 文件。每个调用过的函数的返回值都会在后续进行缓存。
假设我们在运行开发服务器,当你的电脑保存 sdk.ts 时,Turbopack 将接收到系统文件的事件,知道要再次调用 readFile("sdk.ts")。
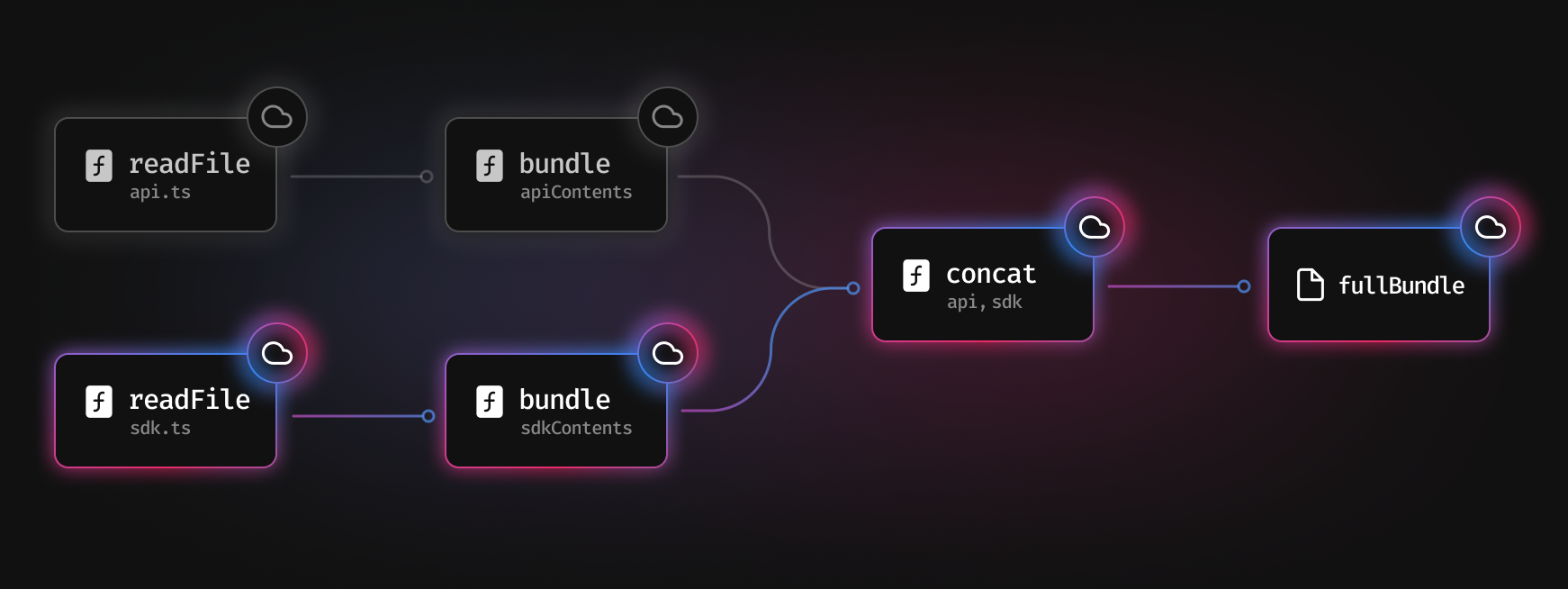
由于 sdk.ts 发生了改变,我们就需要再 构建 一次,然后再重新将文件合并起来。
至关重要的是,api.ts 并未发生改变。我们可以直接从缓存中读取其内容,然后再传递给 concat 函数,这样我们就节省了重复读取和构建文件的时间。
假设一个构建工具有成千上万的文件需要读取和转化,这里心智模型是一样的。你可以像上面一样,通过缓存函数避免重复操作,来节省大量的工作和时间。
缓存
Turbo 引擎目前将缓存放在内存里。这就意味着缓存伴随着整个进程的生命周期,这在开发服务器中是很有用的。当你在 Next v13 运行 next dev --turbo 时,你就开始在用 Turbo 引擎缓存了。当你关闭了开发服务器,缓存就会被清理。
在未来,我们计划将缓存持久化。要么将缓存保存至文件系统,要么就像 Turborepo 那样远程缓存,也就是说 Turbopack 将跨运行、跨机器间支持缓存。
这有什么用?
这个方法令 Turbopack 能够迅速计算出应用的递增式更新,并优化 Turbopack 在开发模式下的更新任务,意味着你的开发服务器可以快速响应文件变化。
未来,持久化缓存将拥抱更快的生产构建。在生产构建中有了函数调用的缓存,将重新构建发生变化的文件,也许能节省大量的时间。
根据请求编译
Turbo 引擎能够为开发服务器提供极快的更新体验,但还有另一个重要的考量 —— 启动时间。开发服务器启动得越快,你就能越快投入工作。
这两种方式可以加快这个过程:提高性能和减少工作量。对于启动开发服务器而言,要减少工作量就得 仅编译需要用到的代码。
页面级编译
两三年前的 Next.js 版本会在开发服务器启动前,编译整个应用代码。在 Next.js [11],我们开始只编译 会被请求到的页面代码。
这个方式比以往更佳,但不还算不上优秀。当你访问 /users 时,我们会构建所有的客户端和服务端模块、动态导入的模块、CSS、图片文件等其它引用资源。这意味着,如果你的页面有很大一部分内容是不可见的,或者是被标签页隐藏掉了,我们仍然还是会将它们进行编译。
请求级编译
聪明的 Turbopack 会知道 仅编译你请求的代码。如果浏览器请求 HTML,我们只编译 HTML,不会编译 HTML 引用的资源。
如果浏览器想要获取 CSS,我们就只编译 CSS,不会编译其引用的图片文件。假设你在 next/dynamic 后面引入了一个大型图表 Library,只有当标签页可见并且图表显示时,这个 Library 才会被编译。Turbopack 甚至知道只有在你打开了 Chrome DevTools 时,才编译 Source Maps
如果我们使用原生 ESM,我们也能得到差不多的效果,除了它需要向服务器发送大量的请求,这在 Why Turbopack 章节就说过了。拥有了请求级编译,减少请求量的同时,还能有原生语言速度的加持。你可以查看 性能测试 章节,了解其显著的性能提升。